



중요한 과제는 케이블 구동 병렬 로봇이 제한된 공간에서 동적 장애물을 탐색하고 피하는 방법에 있습니다.
하얼빈 공과대학교(선전)의 시옹 하오(Xiong Hao) 팀은 SCI&EI 색인 저널 IEEE Robotics and Automation Letters에 발표된 "심투리얼 강화 학습을 통한 이동 기반 케이블 구동 병렬 로봇의 동적 장애물 회피"라는 제목의 논문으로 흥미로운 연구를 수행했습니다.
시옹하오 교수팀은 2024년 지능형 로봇 및 시스템 국제회의(ICRA)에서 관련 연구 결과를 발표할 예정입니다.

연구 초록
연구 배경
CDPR(Cable-Driven Parallel Robots)은 강성 링크 대신 케이블을 사용하여 엔드 이펙터의 위치를 제어하는 새로운 유형의 병렬 로봇입니다.
이 로봇들은 단순한 구조, 낮은 관성, 넓은 작업 영역, 좋은 동적 성능을 가지고 있습니다. 그들은 장비 제조, 의료 재활, 항공 우주 및 기타 분야의 응용 프로그램에 매우 적합합니다. 기하학적 구성을 변경하는 능력 때문에 제한된 환경에서 작업하기에 특히 적합합니다.

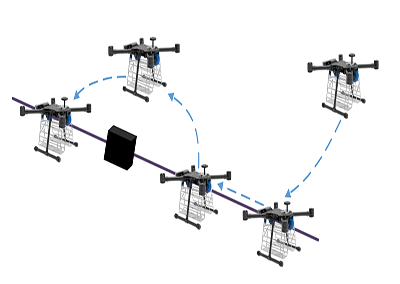
4개의 이동 베이스가 있는 로프 트랙션 평행 로봇
제한된 환경에서 CDPR은 궤적 계획 방법에 의해 고려되지 않는 동적 장애물에 직면할 수 있으며, 장애물을 우회하거나 통과하기 위한 실시간 회피 동작이 필요합니다. 이는 여러 케이블과 모바일 기반에서 발생하는 고차원 상태 공간 및 제약 때문에 어려운 작업입니다.
该이 연구는 CDPR이 장애물을 동적으로 회피하고 충돌을 피하고 필요에 따라 목표 궤적으로 복귀할 수 있는 알고리즘을 제안하여 이 문제를 해결합니다.

CDPR은 궤도를 계획하는 동안 동적 장애물과 마주칠 수 있습니다
장애물 회피 알고리즘
본 연구에서는 강화 학습(RL) 기반의 장애물 회피 제어기(OAC)를 제안하고 이를 궤적 추적 제어기(TTC)에 통합합니다. OAC 설계는 이동 베이스에 연결된 고정 길이 케이블로 CPDR의 실시간 장애물 회피 문제를 해결하기 위해 SAC(Soft Actor Critic) 알고리즘과 주의 모듈을 기반으로 합니다.
이 방법은 CDPR의 여러 제약 조건과 고차원 상태 공간을 처리하여 실시간 동적 장애물 환경에서 동적 장애물 회피를 달성할 수 있습니다.

SAC 알고리즘 기반 장애물 회피 제어기.
RL 기반 OAC는 2단계 훈련과 1단계 훈련이라는 두 가지 훈련 전략을 사용하여 무조코 시뮬레이터에서 훈련되었습니다.
2단계 훈련 전략의 경우, OAC는 약 35분의 훈련 시간으로 50,000 사이클 내에 수렴합니다. 1단계 훈련 전략의 경우, OAC는 500,000 사이클 내에 수렴하여 훈련에 약 5.5시간이 걸립니다. 두 OAC는 궁극적으로 거의 동일한 결과를 달성합니다. 연구는 보상 형성 기술을 사용하는 2단계 훈련 전략이 OAC의 훈련을 빠르게 할 수 있음을 나타냅니다.
실세계 실험
훈련된 RL 기반 OAC 알고리즘을 실제 환경에서 테스트했습니다.
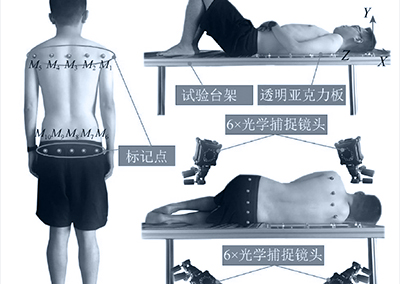
이 실험 설정은 4개의 고정 길이 케이블로 연결된 4개의 이동식 베이스가 있는 케이블 구동 병렬 로봇 (CDPR)으로 구성되었습니다. 두 가지 유형의 장애물이 사용되었습니다: 0.32 미터 높이의 낮은 장애물과 0.92 미터 높이의 높은 장애물.
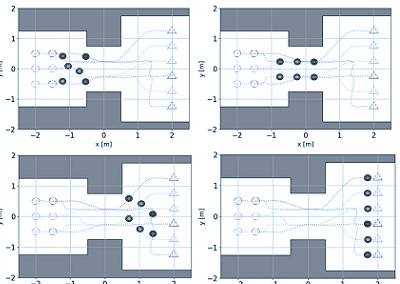
CDPR의 모바일 플랫폼은 더 짧은 장애물을 통과할 수 있었지만 충돌을 피하기 위해 더 높은 장애물 주변을 돌아다녀야 했습니다.
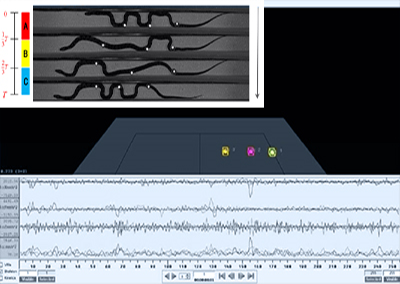
실험 중에 NOKOV 모션 캡처 시스템을 배치하여 케이블의 위치와 방향, 이동기지 및 동적 장애물을 실시간으로 캡처했습니다.

다양한 높이의 장애물에 부딪힐 때 CPDR이 수행하는 회피 기동
RL 기반 OAC 방법은 CDPR이 서로 다른 높이의 장애물 위나 주변을 탐색하기 위해 서로 다른 회피 전략을 사용하도록 성공적으로 안내했습니다.
참조:

































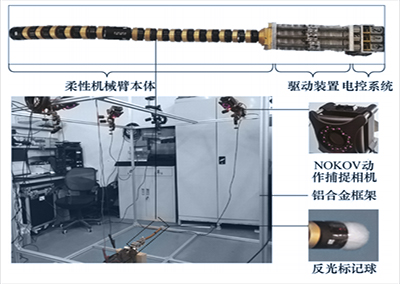



















































문의하기
-
우리는 항상 귀하의 질문에 답변하고 더 많은 정보를 제공하게 되어 기쁩니다.
문제에 대해 알려주시면 최상의 솔루션을 안내해 드리겠습니다.
-
-
- 캡처 볼륨 * m m m
-
선택 해주세요 *
- 제안 수 (옵션)
-
카메라 유형(선택 사항)
-
카메라 수(선택 사항)
- 제출하다